Three months, 30x demand: How we scaled Google Meet during COVID-19

Samantha Schaevitz
Staff Site Reliability Engineer
Learn how our SRE team ramped up to handle high demand for Google Meet in response to COVID-19.
Try Google Workspace at No Cost
Get a business email, all the storage you need, video conferencing, and more.
SIGN UPAs COVID-19 turned our world into a more physically distant one, many people began looking to online video conferencing to maintain social, educational, and workplace contact. As shown in the graph below, this shift has driven huge numbers of additional users to Google Meet.
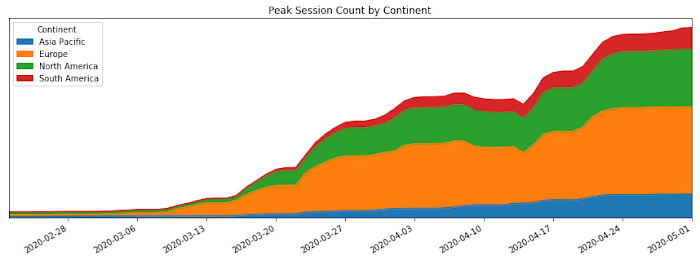
In this post, I’ll share how we ensured that Meet’s available service capacity was ahead of its 30x COVID-19 usage growth, and how we made that growth technically and operationally sustainable by leveraging a number of site reliability engineering (SRE) best practices.
Early alerts
As the world became more aware of COVID-19, people began to adapt their daily rhythms. The virus's growing impact on how people were working, learning, and socializing with friends and family translated to a lot more people looking to services like Google Meet to keep in touch. On Feb. 17, the Meet SRE team started receiving pages for regional capacity issues.
The pages were symptomatic, or black-box alerts, like “Too Many Task Failures” and “Too Much Load Being Shed.” Because Google's user-facing services are built with redundancy, these alerts didn’t indicate ongoing user-visible issues. But it soon became clear that usage of the product in Asia was trending sharply upward.
The SRE team began working with the capacity planning team to find additional resources to handle this increase, but it became obvious that we needed to start planning farther ahead, for the eventuality that the epidemic would spread beyond the region.
Sure enough, Italy began its COVID-19 lockdown soon thereafter, and usage of Meet in Italy began picking up.
A non-traditional incident
At this point, we began formulating our response. True to form, the SRE team began by declaring an incident and kicking off our incident response to this global capacity risk.
It’s worth noting, however, that while we approached this challenge using our tried-and-true incident management framework, at that point we were not in the middle of, or imminently about to have, an outage. There was no ongoing user impact. Most of the social effects of COVID-19 were unknown or very difficult to predict. Our mission was abstract: we needed to prevent any outages for what had become a critical product for large amounts of new users, while scaling the system without knowledge of where the growth would come from and when it would level off.
On top of that, the entire team (along with the rest of Google) was in the process of transitioning into an indefinite period of working from home due to COVID-19. Even though most of our workflows and tools were already accessible from beyond our offices, there were additional challenges associated with running such a long-standing incident virtually.
Without the ability to sit in the same room as everyone else, it became important to manage communication channels proactively to ensure we all had access to the information needed to achieve our goals. Many of us also had additional, non-work related challenges, like looking after friends and family members as we all adjusted. While these factors created extra challenges for our response, tactics like assigning and ramping up standbys and proactively managing ownership and communication channels helped us overcome these challenges.
Nevertheless, we carried on with our incident management approach. We started our global response by establishing an Incident Commander, Communications Lead, and Operations Lead in both North America and Europe so that we had around-the-clock coverage.
As one of the overall Incident Commanders, my function was like that of a stateful information router—albeit with opinions, influence, and decision-making power. I collected status information about which tactical problems lingered, who was working on what, and on the contexts that affected our response (e.g. governments’ COVID-19 responses), and then dispatched work to people who were able to help. By sniffing out and digging into areas of uncertainty (both in problem definition: “Is it a problem that we're running at 50% CPU utilization in South America?” and solution spaces: “How will we speed up our turn-up process?”), I coordinated our overall response effort and ensured that all necessary tasks had clear owners.
Not long into the response, we realized that the scope of our mission was huge and the nature of our response would be long-running. To keep each contributor’s scope manageable, we shaped our response into a number of semi-independent workstreams. In cases where their scopes overlapped, the interface between the workstreams was well-defined.
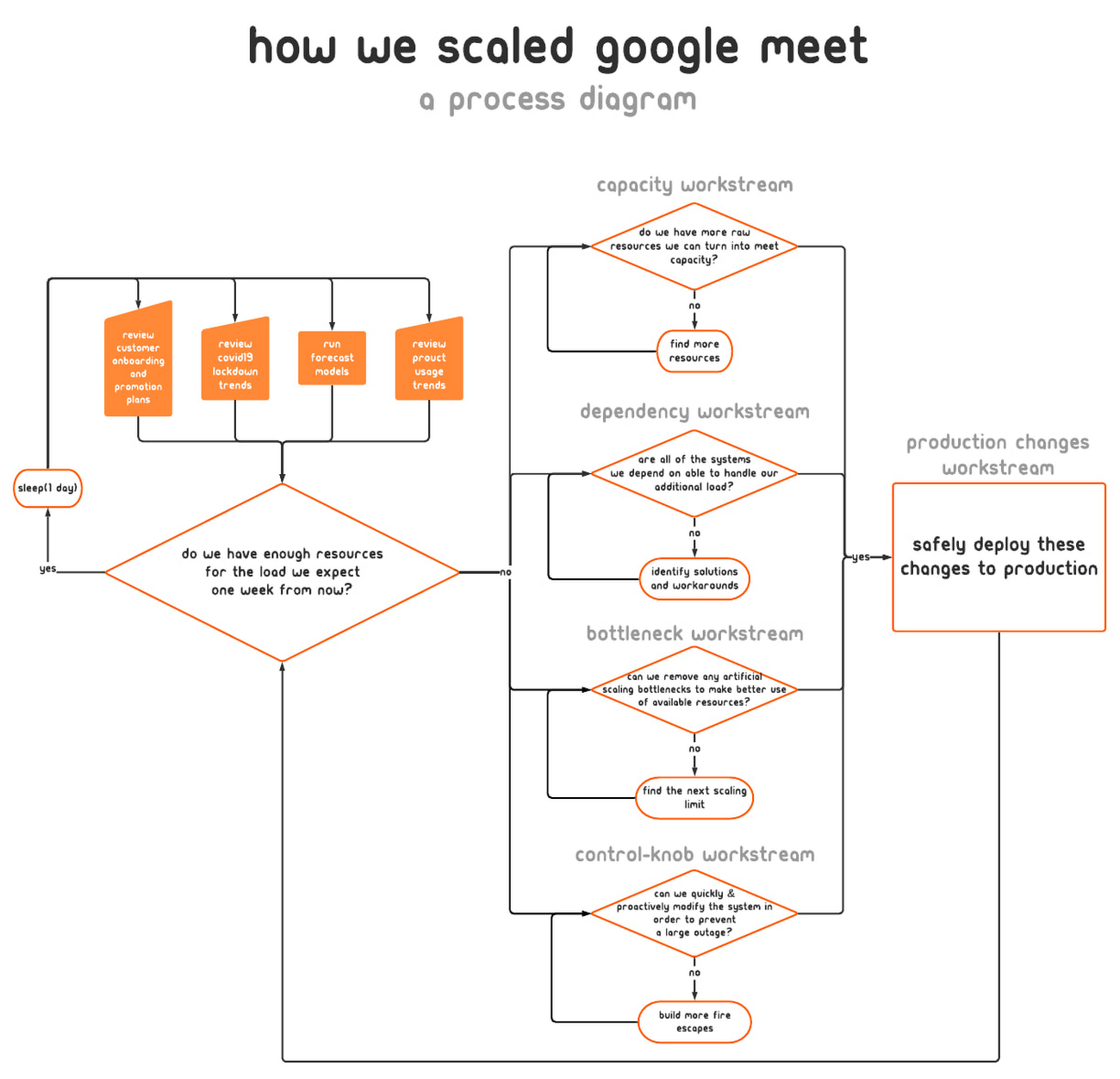
We set up the following workstreams, visible in the diagram above:
- Capacity, which was tasked with finding resources and determining how much of the service we could turn up in which places.
- Dependencies, which worked with the teams that own Meet’s infrastructure (e.g., Google’s account authentication and authorization systems) to ensure that these systems also had enough resources to scale with the usage growth.
- Bottlenecks, which was responsible for identifying and removing relevant scaling limits in our system.
- Control knobs, which built new generic mitigations into the system in the case of an imminent or in-progress capacity outage.
- Production changes, which safely brought up all of the found capacity, re-deployed servers with newly-optimized tuning, and pushed new releases with additional control knobs ready to be used.
As incident responders, we continuously re-evaluated if our current operational structure still made sense. The goal was to have as much structure as required to operate effectively, but no more. With too little structure, people make decisions without having the right information, but with too much structure, people spend all of their time in planning meetings.
This was a marathon, and not a sprint. Throughout, we regularly checked in to see if anyone needed more help, or needed to take a break. This was essential in preventing burnout during such a long incident.
To help prevent exhaustion, each person in an incident response role designated another as their “standby.” A standby attended the same meetings as the role’s primary responder; got access to all relevant documents, mailing lists, and chat rooms; and asked the questions they’d need answers to if they had to take over for the primary without much notice. This approach came in handy when any of our responders got sick or needed a break because their standby already had the information they needed to be effective right away.
Building out our capacity runway
While the incident response team was figuring out how best to coordinate the flow of information and work needed to resolve this incident, most of those involved were actually addressing the risk in production.
Our primary technical requirement was simply to keep the amount of regionally available Meet service capacity ahead of user demand. With Google's more than 20 data centers operating around the world, we had robust infrastructure to tap into. We quickly made use of raw resources already available to us, which was enough to approximately double Meet’s available serving capacity.
Previously, we relied on historical trends to establish how much more capacity we’d need to provision. But because we could no longer rely on the extrapolation of historical data, we needed to begin provisioning capacity based on predictive forecasts. To translate those models into terms our production changes team could act upon in production, the capacity workstream needed to translate the usage model into how much additional CPU and RAM we needed. Building this translation model is what later enabled us to speed up the process of getting available capacity in production, by teaching our tools and automation to understand it.
Soon, it became clear that merely doubling our footprint size was not going to be enough, so we started working against a previously unthinkable 50x growth forecast.
Reducing resource needs
In addition to scaling up our capacity, we also worked on identifying and removing inefficiencies in our serving stack. We could bucket much of this work into a couple of categories: tuning binary flags and resource allocations and rewriting code to make it cheaper to execute.
Making our server instances more resource-efficient was a multi-dimensional effort—the goal could be phrased as “the most requests handled at the cheapest resource cost, without sacrificing user experience or reliability of the system.”
Some investigative questions we asked ourselves included:
Could we run fewer servers with larger resource reservations to reduce computational overhead?
Had we been reserving more RAM than we needed, or more CPU than we needed? Could we better use those resources for something else?
Did we have enough egress bandwidth at the edge of our network to serve video streams in all regions?
Could we reduce the amount of memory and CPU needed by a given server instance by subsetting the number of backend servers in use?
Even though we always qualified new server shapes and configurations, at this point, it was very much worth reevaluating them. As Meet usage grew, its usage characteristics—like how long a meeting lasts, the number of meeting participants, how participants share audio time—also shifted.
As the Meet service required ever more raw resources, we began noticing that a significant percentage of our CPU cycles were being spent on process overhead like keeping connections to monitoring systems and load balancers alive, rather than on request handling.
In order to increase the throughput, or “number of requests processed per CPU per second,” we increased our processes’ resource specification in terms of both CPU and RAM reservation. This is sometimes called running “fatter” tasks.

In the example data above, you will notice two things: that all three of the instance specifications have the same computational overhead (in red), and that the larger the overall CPU reservation of an instance, the more request throughput it has (in yellow). With the same total amount of CPU allocated, one instance of the 4x shape can handle 1.8 times as many requests as the four instances with the baseline shape. This is because the computational overhead (like persisting debug log entries, checking if network connection channels are still alive, and initializing classes) doesn’t scale linearly with the number of incoming requests the task is handling.
We kept trying to double our serving tasks’ reservations while cutting in half the number of tasks across our fleet until we hit a scaling limitation.
Of course, we needed to test and qualify each of these changes. We used canary environments to make sure that these changes behaved as expected and didn’t introduce or hit any previously undiscovered limitations. Similar to how we qualify new builds of our servers, we qualified that there weren’t any functional or performance regressions, and that the desired effects of the changes were indeed realized in production.
We also made functional improvements to our codebase. For example, we rewrote an in-memory distributed cache to be more flexible in how it sharded entries across task instances. This, in turn, let us store more entries in a single region when we grew the number of server instances in a cluster.
Crafting fire escapes
Though our confidence in our usage growth forecasts was improving, these predictions were still not 100% reliable. What would happen if we ran out of serving capacity in a region? What would happen if we saturated a particular network link? The control knob workstream’s goal was to provide satisfactory, if not ideal, answers to those kinds of questions. We needed an acceptable plan for any black swans that arrived on our consoles.
A group began working to identify and build more production controls and fire escapes—all of which we hoped we wouldn't need. For example, these knobs would allow us to quickly downgrade the default video resolution from high-definition to standard-definition when someone joined a Meet conference. That change would buy us some time to course-correct using the other workstreams (provisioning and efficiency improvements) without substantial product degradation, but users would still be able to upgrade their video quality to high-definition if they wanted to.
Having a variety of instrumented controls like this built, tested, and ready to go bought us some additional runway if our worst-case forecasts weren’t accurate—along with some peace of mind.
Operational sustainability
This structured response involved large numbers of Googlers in a variety of roles. This meant that to keep making progress throughout the incident, we also needed some serious coordination and intentional communications.
We held daily handover meetings between our two time zones to accommodate Googlers based in Zurich, Stockholm, Kirkland, Wash., and Sunnyvale, Calif. Our communications leads provided regular updates to numerous stakeholders across our product team, executives, infrastructure teams, and customer support operations so that each team had up-to-date status information when they made their own decisions. The workstream leads used Google Docs to keep shared status documents updated with current sets of risks, points of contact, ongoing mitigation efforts, and meeting notes.
This approach worked well enough to get things going, but soon began to feel burdensome. We needed to lengthen our planning cycle from days to weeks in order to meaningfully reduce the amount of time spent coordinating, and increase the time we spent actually mitigating our crisis.
Our first tactic here was to build better and more trustworthy forecasting models. This increased predictability meant we could stabilize our target increase in serving capacity for the whole week, rather than just for tomorrow.
We also worked to reduce the amount of toil necessary to bring up any additional serving capacity. Our processes, just like the systems we operate, needed to be automated.
At that point, scaling Meet’s serving stack was our most work-intensive ongoing operation, due to the number of people who needed to be up-to-date on the latest forecast and resource numbers, and the number of (sometimes flaky) tools involved in certain operations.

As outlined in the life-cycle diagram above, the trick to automating these tasks was incremental improvements. First we documented tasks, and then we began automating pieces of them until finally, in the ideal case, the software could complete the task from start to finish without manual intervention.
To accomplish this, we committed a number of automation experts from within and outside the Meet organization to focus on tackling this problem space. Some of the work items here included:
Making more of our production services responsive to changes in an authoritative, checked-in configuration file
Augmenting common tools to support some of Meet’s more unique system requirements (e.g., its higher bandwidth and lower latency networking requirements)
Tuning regression checks that had become more flaky as the system grew in scale
Automating and codifying these tasks made a significant dent in the manual operations required to turn up Meet in a new cluster or to deploy a new binary version that would unlock performance improvements. By the end of this scaling incident, we were able to fully automate our per-zone, per-serving job capacity footprint, which precluded hundreds of manually constructed invocations of command-line tools. This freed up time and energy for more than a few engineers to work on some of the more difficult (but equally important) problems.
At this point in scaling our operations, we could move to “offline” handoffs between sites via email, further reducing the number of meetings to attend. Now that our strategy was solidified and our runway was longer, we moved into a more purely tactical mode of execution.
Soon after, we wound down our incident structure and began to operate the remaining work more like how we'd run any long-term project.
Results
By the time we exited our incident, Meet had more than 100 million daily meeting participants. Getting there smoothly was not easy or straightforward; the scenarios the Meet team explored during disaster and incident response tests prior to COVID-19 did not encompass the length or the scale of increased capacity requirements we encountered. As a result, we formulated much of our response on the fly.
There were plenty of hiccups along the way, as we had to balance risk in a different way than we normally do during standard operations. For example, we deployed new server code to production with less canary baking time than normal because it contained some performance fixes that bought us additional time before we were due to run out of available regional capacity.
One of the most crucial skills we honed throughout this two month-long endeavour was the ability to catalog, quantify, and qualify risks and payoffs in a way that was flexible. Everyday, we learned new information about COVID-19 lockdowns, new customers’ plans to start using Meet, and available production capacity. Sometimes this new information made obsolete the work we’d started the day before.
Time was of the essence, so we couldn’t afford to treat each work item with the same priority or urgency, but we also couldn’t afford not to hedge our own forecast models. Waiting for perfect information wasn’t an option at any point, so the best we could do was build out our runway as much as possible, while making calculated but quick decisions with the data we did have.
All of this work was only possible because of the savvy, collaborative, and versatile people across a dozen teams and as many functions—SREs, developers, product managers, program managers, network engineers, and customer support—who worked together to make this happen.
We ended up well-positioned for what came next: making Meet available for free to everyone with a Google account. Normally, opening the product up to consumers would have been a dramatic scaling event all on its own, but after the intense scaling work we'd already done, we were ready for the next challenge.



