
{kind=link}
Babies learn words by matching images to sounds. A mother says "dog" and points to a dog. She says "tree" and points to a tree. After repeating this process thousands of times, babies learn to recognize both common objects and the words associated with them.
Researchers at MIT have developed software with the same ability to learn to recognize objects in the world using nothing but raw images and spoken audio. The software examined about 400,000 images, each paired with a brief audio clip describing the scene. By studying these labels, the software was able to correctly label which portions of the picture contained each object mentioned in the audio description.
For example, this image comes with the caption "a white and blue jet airliner near trees at the base of a low mountain."

A video shows the software labeling the different parts of the image as the audio caption plays—first highlighting the airplane, then the trees, and finally the mountain.
What's really remarkable about this software is that it was able to do this without any pre-existing knowledge of either objects in the world or the English language. This isn't the first research to match images to spoken descriptions, but earlier efforts used neural networks that were pre-trained using labeled images from the popular ImageNet database of images labeled with textual categories.
The new MIT software, in contrast, learns to recognize words and images entirely by examining raw images and audio files. It doesn't have any pre-existing knowledge about common objects in the world, and the software doesn't have any hard-coded ideas about how to parse language.
Like a lot of modern image-recognition software, the MIT team's image-recognition program is built around convolutional neural networks. This type of neural network is particularly adept at recognizing the same pattern of pixels in different parts of an image. The MIT software also has a separate, deep neural network for speech recognition—it also uses convolutional layers.
The results of these two networks are then combined in a way that compares each region of the image against each portion of the audio file. The network is structured in a way that allows the software to draw correlations between portions of the image network and portions of the audio network that "light up" at the same time.
The result looks something like this:
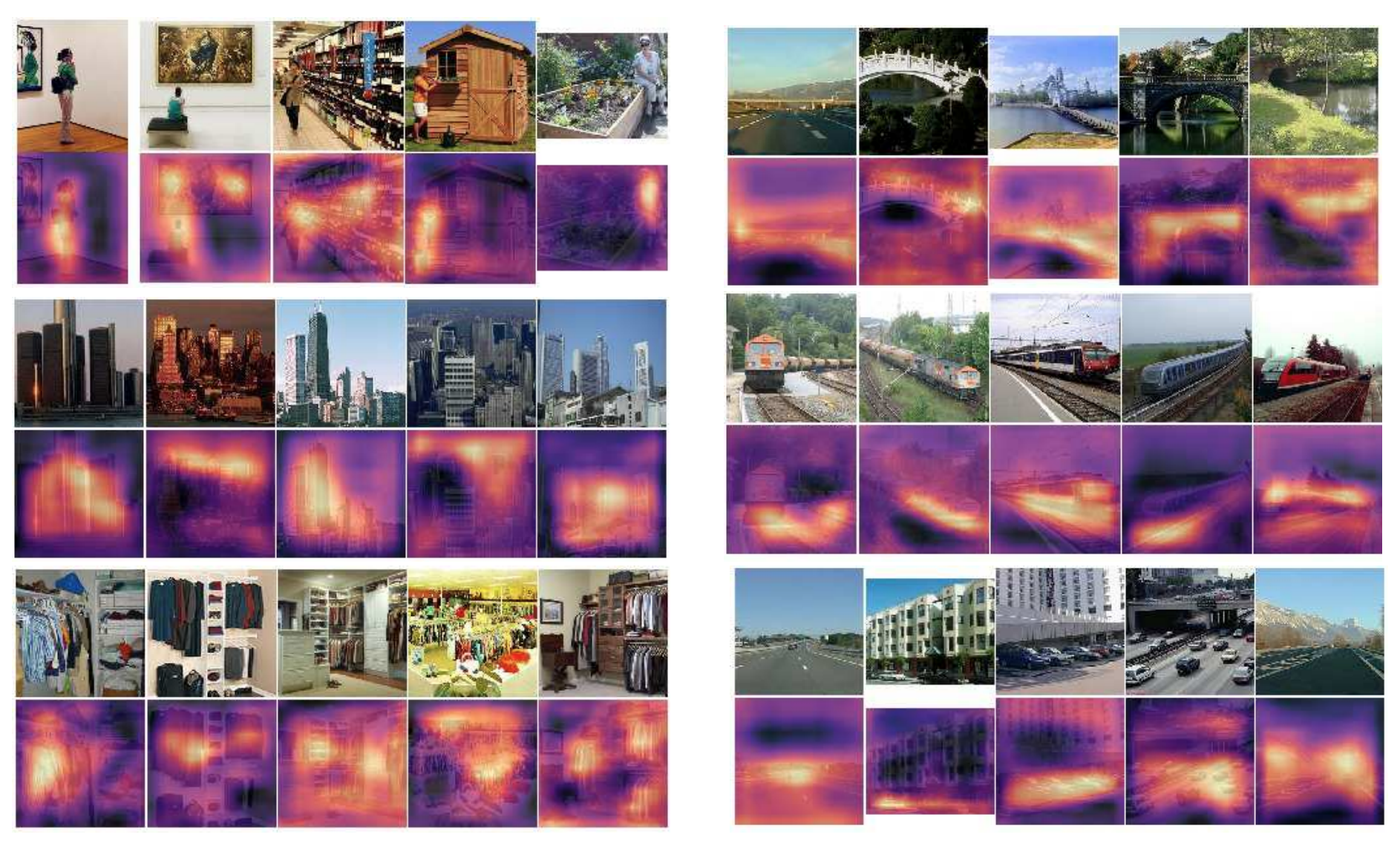
Here each photo has a heatmap directly below it showing where the algorithm believes the object in question is located. The software isn't perfect; it appears to identify a grocery store shelf as a woman in one upper-left picture, for example. Still, it's remarkable how well the software is able to infer the structure of photos and spoken audio without human programmers having explicitly encoded any pre-existing knowledge about the world.
reader comments
67